
缓冲区溢出与 ret2libc:从栈帧布局到控制流劫持
这是一篇软件安全课程笔记,系统梳理了栈与堆的内存布局、经典 BOF(缓冲区溢出)攻击链路以及 ret2libc / ROP 等现代利用思路,并总结了常见防御技术与考试/实验要点。
[迁移说明] 本文最初发布于
blog.zzw4257.cn,现已迁移并在本站进行结构化整理与增强。
BOF & ret2libc
前置:内存布局和函数调用
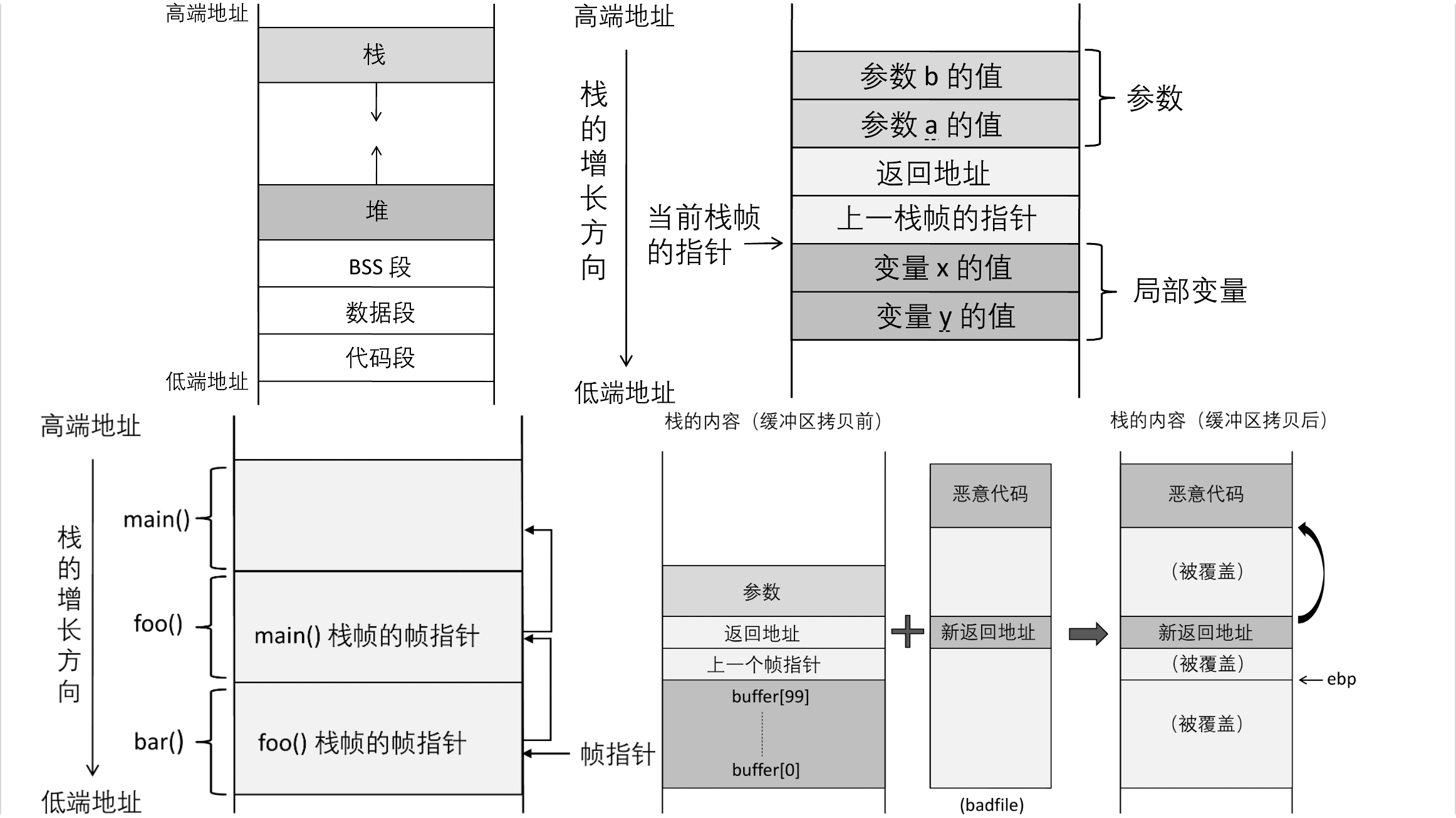
(描述按照从高到低进行)
栈,上到下,函数局部变量,栈帧【倒过来的参数+ret+pfp前帧指针+lv局部变量】
堆,下到上,动态分配内存,被loc系列管理
BSS未初始化,0填充,静态+全局
data初始化静态+全局
text可执行,一般只读
我们直接看一个加强版的例子
#include <stdio.h>
#include <stdlib.h>
// ========== 静态存储区:DATA 段 (已初始化静态数据) / BSS 段 (未初始化静态数据) / 常量区 ==========
// 1. DATA 段: 已初始化的全局变量
int initialized_global_x = 100;
// 2. BSS 段: 未初始化的全局变量
int uninitialized_global_y;
// 3. 常量区/只读数据段: 全局常量
const float GLOBAL_PI = 3.14159f;
// 4. 常量区/只读数据段: 字符串字面量
char *string_literal_ptr = "Hello, World!";
// 5. 代码段: 函数的代码指令
void my_function(int param_a, int param_b)
{
// 6. 栈: 函数参数
// param_a 和 param_b 存储在栈帧中
// 7. 栈: 局部变量
int local_i = 10;
char local_str[20]; // 数组本身(指针)在栈上,内容也在栈上
// 8. DATA 段: 已初始化的局部静态变量
static int initialized_static_var = 500;
// 9. BSS 段: 未初始化的局部静态变量
static long uninitialized_static_var;
// 局部常量 (通常存储在栈上,或被编译器优化)
const int LOCAL_CONST = 20;
// 局部静态变量的生命周期是整个程序运行期间
initialized_static_var++;
}
int main(void)
{
// 10. 栈: main 函数内的局部变量
int stack_var_a = 2;
// 11. 栈: 指针变量本身
int *heap_ptr = NULL;
// 12. 堆: 动态分配的内存块
heap_ptr = (int *) malloc(2 * sizeof(int));
if (heap_ptr)
{
heap_ptr[0] = 5; // 存储在堆中
heap_ptr[1] = 6; // 存储在堆中
}
my_function(1, 2); // 函数调用将创建一个新的栈帧
if (heap_ptr) {
free(heap_ptr); // 释放堆内存
}
return 0;
}帧指针寄存器 (ebp) 始终指向前一个栈帧指针保存的地址,ret=[ebp+4]
BOF执行以及多种情况讨论
关键起手三部曲(两编译一服务)
- -z execstack 栈可执行
- -fno-stack-protector 金丝雀的处理,bof和ret之间的随机检查点
- sysctl -w kernel.randomize_va_space=0 ASLR关闭,本质是对栈堆之间可变层的随机加厚(注意关掉ASLR后,依旧不可预测栈/堆/libc位置,但其在elf构建过程中进行一个独立于ASLR熵的随机化过程,ASLR的随机化在ELF加载器上实现)【在 32 位 Linux 系统上,栈只有 19 比特的熵,524, 288 种可能性,堆为 13 比特 ,kernel.randomize_va_space是对栈堆随机化的约束】
在开始前我们首先再一次明确自己干嘛,我们需要从缓冲区往上(高地址)尝试把badfile插到ret位置上,假设我们只是纯粹把非法的放到ret上会收到Segmentation fault (core dumped)
我们可以进行攻击的两个点
- ASLR的取消,大多数操作系统把栈(每个进程有一个栈)放在固定的起始地址(不同进程的同一个虚拟地址)
- 大多数程序的栈并不深
接下来解决的一个关键问题是,我们需要在ret处塞入精确的恶意注入代码的位置(被拷贝在bof中,但具体位置一般需要推/调,亦或者不方便获取)吗
然后基础攻击逻辑可以被总结为构建NOP Sled(和栈金丝雀 StackGuard相悖离)
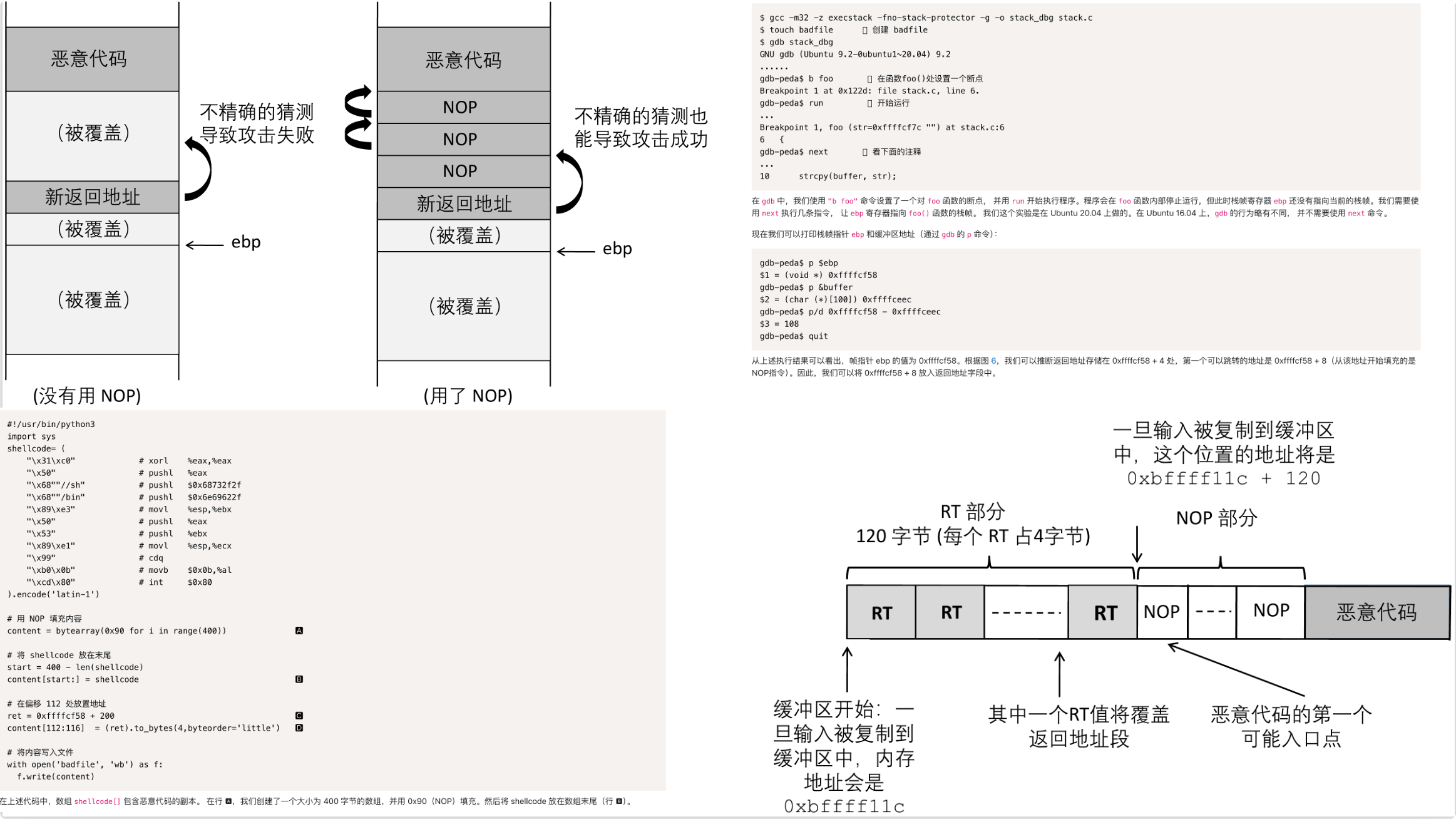
可以看一个最简单的例子,反正就是进去你想要利用的函数的,找出指向当前栈帧的ebp和缓冲区起点&buffer,然后根据套路进行。具体的shellcode的构造不用深究,重点是后续
- 指导ebp,知道&buffer,则可以简单构造ebp-&buffer+4开始的精准ret投放
112是ebp-buffer+4也就是从buffer底往上数第一个栈帧外地址,在这里放置ret即可
这里一个非常重要的细节就是ret的地址绝对不能包含一个字节0,否则也就会出现badfile的内容有0
如0xffffcf58+0xA8=0xffffd000
小心bash/dash禁止被set-uid进程执行
- 知道&buffer不知道ebp,则不知道大小,那么可以暴力填充ret可能位置,这个喷洒范围有一些细节讨论其实可以忽略

64位,ebp->rbp,ret=[rbp+8],前面有0(这个实际上是Sv39-48),缓冲区足够塞下shellcode
利用小端序 0x7fffffffaa88,则从低地址到高地址存储在内存中的数据为 88 aa ff ff ff 7f 00 00
那么实际上逆向思维一下,之前一直把shellcode放后面,假设缓冲区大一点,我们可以塞在开头,然后ret复写在payload最后,刚好截断,截断就截断然后指回开头
64位缓冲区无法塞下shellcode
这其实是个自欺欺人的问题,shellcode不显式赛道缓冲区,只要其能够被利用函数传参,其已经在栈上了,这个没有什么通用的办法,通过gdb把栈帧之间距离找出来,或者直接计算也行(实际上可以卡范围然后暴力)
BOF防御相关
函数用 strncpy、snprintf、strncat 和 fgets,需要明确缓冲区最大长度,不过可以通过强制超出缓冲区实际大小同样制造溢出攻击,等效于改用libsafe 函数库
Stackshield (Angelfire.com 2000) 和 StackGuard (Cowan et al. 1998)分别是堆ret进行备份检查,在ret和buffer之间构建随机化哨兵canary
ASLR是loader做的好习惯
BOF总结和ret2libc引子
栈帧结构
(高地址)
--------------------
...
函数参数 (arg_N)
...
函数参数 (arg_0)
--------------------
返回地址 (Return Address) <-- EIP 将在函数返回后跳转到这里
--------------------
旧 EBP (Old EBP) <-- 保存调用者的 EBP 值
-------------------- <-- 当前函数的 EBP 指向这里
局部变量 (local_var)
...
缓冲区 (Buffer)
...
-------------------- <-- ESP 指向这里
(低地址)| 危险函数 | 功能 | 漏洞点 |
|---|---|---|
| strcpy() | 字符串复制 | 不检查目标缓冲区大小,持续复制直到遇到源字符串的 \0。 |
| strcat() | 字符串拼接 | 同上,在目标字符串后拼接,不检查拼接后的总长度。 |
| sprintf() | 格式化字符串输出 | 类似于 printf,但输出到字符串。若格式化内容过长,则溢出。 |
| gets() | 从标准输入读取 | 极度危险。无任何方法限制输入长度,已被C11标准废弃。 |
| scanf() | 格式化输入 | 使用 %s 等格式符时,若无宽度限制,可能导致溢出。 |
- 控制流劫持的关键:栈上的返回地址决定了函数执行完毕后的下一条指令地址。攻击的核心目标就是覆盖这个值。
- EBP的作用:在函数执行期间,EBP是固定的,因此编译器通过[EBP + offset]访问参数(如 [EBP+8] 是第一个参数),通过[EBP - offset]访问局部变量。这使得偏移量计算成为可能。
- 调用链:旧 EBP 像一条链表,将所有栈帧链接起来,用于在函数返回时恢复调用者的栈帧。
- 压栈顺序:C语言的cdecl调用约定中,函数参数从右到左依次入栈。
Payload是攻击者精心构造的、作为输入传递给程序的恶意数据流。其结构是攻击成功的关键,也是实验和考试的重点。
经典Payload结构:
[ NOP Sled | Shellcode | Padding | Return Address ]- NOP Sled (空操作雪橇):
- 作用: 大量连续的 NOP (No-Operation) 指令(机器码通常为 0x90)。EIP 只要跳到这个“雪橇”的任何位置,就会像滑雪一样“滑”到后面的 Shellcode 并开始执行。
- 痛点解决: 大幅降低了对 Return Address 精准度的要求。由于栈地址可能因环境有微小变化,直接跳转到 Shellcode 起始地址容易失败。有了NOP Sled,只需让返回地址指向这个雪橇的大致范围即可。
- Shellcode (恶意代码):
- 定义: 一小段用于实现特定攻击目的的机器码,最常见的目标是获取一个shell(命令行解释器),故得名。
- 考点: Shellcode必须是位置无关代码 (Position-Independent Code),因为它被注入到目标进程后,其内存地址是不确定的。同时,Shellcode中不能包含 \0 (NULL) 字节,否则会被 strcpy 等函数截断,导致Payload复制不完整。
- Padding (填充物):
- 作用: 任意字节,用于填满 Shellcode 和 Return Address 之间的空隙,确保 Return Address 能被放置在正确的位置上,精准覆盖栈上的原返回地址。
- Return Address (返回地址):
- 作用: 整个Payload的“导航系统”。这个地址将被用来覆盖原始的返回地址。
- 指向: 它必须指向Payload内部的某个地址,通常是NOP Sled的起始区域。
- 核心痛点 - 字节序 (Endianness): x86架构是小端字节序 (Little-Endian)。地址 0xbffff180 在内存中必须表示为 \x80\xf1\xff\xbf。这是初学者最容易出错的地方,也是必考点。
- NOP Sled (空操作雪橇):
- 确定偏移量 (Offset): 计算从目标缓冲区起始地址到返回地址存储位置的精确字节数。这是最关键的一步,通常使用 GDB 调试器完成。
- 在GDB中,在函数入口设置断点,查看 &buffer 和 $ebp 的值。
- 偏移量 = ($ebp - &buffer) + 4 (旧EBP) 。或者更直接地,找到返回地址的精确地址,减去缓冲区的起始地址。
- 构造Payload: 准备好NOP Sled, Shellcode, 并计算好需要填充的Padding长度。
- 确定返回地址: 确定一个合适的地址,使其落在NOP Sled上。这个地址通常是缓冲区地址加上一个小的偏移量。
- 注入与触发: 将构造好的Payload作为输入(例如写入文件,通过网络发送),让目标程序读入并触发strcpy等危险函数,造成溢出。
- 成功利用: 函数返回,EIP 跳转到NOP Sled,滑向Shellcode,执行恶意代码,攻击成功。
当溢出发生在由 malloc 分配的堆内存区域时,称为堆溢出。
攻击目标: 与栈溢出直接覆盖返回地址不同,堆溢出通常通过破坏堆的元数据 (Heap Metadata) 来实现攻击。这些元数据是 malloc 库用来管理内存块(如记录块大小、前后指针等)的内部数据结构。
典型利用方式 (unlink):
- 原理: glibc 的 malloc 实现中,空闲的内存块通过一个双向链表(free list)来管理。每个空闲块头部都有 fd (forward) 和 bk (backward) 指针。当调用 free() 合并相邻空闲块时,会执行一个 unlink 宏操作,其核心是 P->fd->bk = P->bk; P->bk->fd = P->fd;。
- 攻击: 攻击者通过堆溢出,精心篡改一个即将被释放的堆块的 fd 和 bk 指针。当 unlink 操作发生时,上述指针赋值操作就变成了向任意地址写入任意值 (Arbitrary Write)。
- 痛点: 攻击者可以利用这个“任意写”能力,去覆盖函数指针(如 .dtors 析构函数表、GOT表条目)或者返回地址,从而劫持控制流。
与栈溢出对比:
- 复杂度: 堆溢出利用比栈溢出复杂得多,需要深入理解特定 malloc 实现的内部机制。
- 触发: 触发时机不确定,通常需要等待 free() 函数被调用。
- 威力: 更为隐蔽和强大,能够实现更精细的内存篡改。
地址中的NULL字节: 64位(x86-64)架构的地址虽然是64位,但典型Linux系统中实际使用的只有低48位,高16位通常为0。这意味着几乎所有地址都包含 \x00。
- 痛点: strcpy 等函数会因 \x00 而截断Payload,导致包含完整地址的 Return Address 无法被完整复制。
- 绕过思路: 将Shellcode放在返回地址之前,并且返回地址只覆盖原地址的低位字节,寄希望于高位字节(通常是 0x00…)保持不变。这依赖于原始栈地址与目标地址高位恰好相同。
参数传递: x86-64架构下,函数的前6个参数通过寄存器 (RDI, RSI, RDX, RCX, R8, R9) 传递,而非栈。这使得通过溢出来修改函数参数变得更加困难。
| 防御技术 | 英文简称 | 层面 | 原理 | 痛点/绕过方法 |
|---|---|---|---|---|
| 栈保护 (Stack Canaries) | SSP / ProPolice | 编译器 | 在返回地址前插入一个随机的特殊值(Canary,金丝雀)。函数返回前,检查该值是否被改变。若改变,则认为发生溢出,立即终止程序。 | - 泄露Canary值。 - 逐字节爆破 (Brute-force)。 - 攻击其他目标,如异常处理结构。 |
| 地址空间布局随机化 | ASLR | 操作系统 | 每次程序运行时,将其栈、堆、共享库等内存区域的基地址随机化。 | - 暴力破解:在32位系统上,随机化熵不高,可通过大量尝试命中。 - 信息泄露:利用其他漏洞泄露一个地址,就能推算出其他模块的地址。 - NOP Sled & Heap Spray: 增大命中概率。 |
| 数据执行保护 | DEP/NX/XN | 硬件 (CPU) + OS | 将内存页标记为不可执行。通常,栈和堆被标记为不可执行。即使攻击者成功将Shellcode注入并跳转,CPU也会触发异常,阻止代码执行。 | 核心绕过技术:返回导向编程 (ROP)。不注入新代码,而是利用程序自身和共享库中已存在的代码片段 (gadgets),通过精心构造的返回地址链来串联执行,完成攻击。这是现代漏洞利用的基石。 |
| 位置无关可执行文件 | PIE | 编译器+链接器 | 将主程序代码段的基地址也随机化,是ASLR的完全体。 | 绕过方法同ASLR,但难度更大,因为连代码段的固定地址“跳板”都没有了。 |
ROP是绕过DEP/NX的标准和主流方法,也就是常说的ret2libc。
核心思想: 借刀杀人。攻击者不再注入自己的代码,而是利用目标程序内存中已有的、可执行的代码片段。
Gadget (小工具): ROP利用的基本单位。一个Gadget通常是一段以 ret 指令结尾的、短小的指令序列。例如 pop eax; ret;。
攻击流程:
攻击者在程序的内存空间(尤其是libc等共享库)中搜索大量的Gadgets。
通过缓冲区溢出,覆盖栈上的返回地址以及之后的一系列数据。
被覆盖的栈布局不再是 [新返回地址],而是一个Gadget地址链和参数的序列:
[Gadget1_Addr | Arg1 for Gadget1 | Gadget2_Addr | Arg2 for Gadget2 | ...]第一个 ret 跳转到 Gadget1。Gadget1 执行一些操作(如 pop rdi),然后执行自己的 ret。这个 ret 会从栈上弹出 Gadget2_Addr 到 EIP,从而跳转到第二个Gadget。
如此往复,像链条一样将多个Gadgets串联起来,执行复杂的操作,最终达到调用 system(“/bin/sh”) 等目的。
BOF例题

S4.1
Answer: The address of the function parameter a is determined by the calling convention and is pushed onto the stack by the caller function before foo is called. The address of the local variable x is determined by the compiler as a fixed offset from the stack pointer or frame pointer. When the function foo is entered, space for x is allocated on the stack by moving the stack pointer.
中英文分析: 这个问题询问函数参数 a 和局部变量 x 的地址是如何在运行时确定的。
- 函数参数 (function parameter)
a的地址是由调用者 (caller) 决定的。在调用foo函数之前,调用者会根据调用约定 (calling convention) 将参数a的值压入栈 (stack) 中。因此,a的地址位于调用者函数的栈帧 (stack frame) 附近。 - 局部变量 (local variable)
x的地址是由编译器 (compiler) 决定的。编译器会计算出x相对于当前函数栈帧指针 (Frame Pointer, FP) 或栈顶指针 (Stack Pointer, SP) 的一个固定偏移量 (offset)。当foo函数开始执行时,程序会通过移动栈顶指针来为x在内的所有局部变量分配空间,x的地址就是 그때的栈顶指针加上这个固定的偏移量。
S4.2
Answer:
i: Located in the Data Segment (specifically, the initialized data segment,.data), because it’s a global variable with an initial value.ptr: The pointer variableptritself is a local variable, so it is located on the Stack. However, the memory it points to (malloc(sizeof(int))) is allocated from the Heap.buf: This is a local array, so it is located on the Stack.j: This is an uninitialized local variable, located on the Stack.y: This is astaticlocal variable. It is located in the BSS Segment (Block Started by Symbol) because it is uninitialized. If it were initialized (e.g.,static int y = 1;), it would be in the Data Segment.
中英文分析: 这个问题考察不同类型变量在内存中的存储区域。
i是一个已初始化的全局变量,存储在数据段 (Data Segment)。ptr本身是一个局部变量,这个指针变量存储在栈 (Stack) 上。但它指向的内存是通过malloc动态分配的,这块内存在堆 (Heap) 上。buf是一个局部数组,它的大小在编译时确定,因此它被分配在栈 (Stack) 上。j是一个普通的局部变量,同样分配在栈 (Stack) 上。y是一个static局部变量。它的生命周期是整个程序的运行时间,而不是函数调用期间。因为它没有被初始化,所以它被存储在 BSS 段 (BSS Segment)。如果它被初始化了,就会被存储在数据段。
S4.3
Answer: Here is a diagram of the function stack frame for bof, assuming a standard calling convention where the stack grows from high memory addresses to low memory addresses.
|-------------------| <-- High Memory Address
| char *str | (Function Argument)
|-------------------|
| Return Address | (Address to return to in the caller)
|-------------------|
| Old Frame Pointer | (Caller's EBP/FP)
|-------------------|
| |
| char buffer[24] | (Local Variable)
| |
|-------------------| <-- Low Memory Address / Current Stack Pointer (ESP)中英文分析: 这个问题要求画出 bof 函数的栈帧 (stack frame) 结构。在一个典型的从高地址向低地址增长的栈模型中,函数调用的过程如下:
- 调用者 (caller) 将函数参数 (
char *str) 从右到左压入栈中。 - 调用者执行
call指令,该指令将返回地址 (Return Address) 压入栈中。 - 被调用函数 (
bof) 开始执行,它首先将调用者的帧指针 (Frame Pointer)(也称为基址指针 EBP)压入栈,然后设置自己的帧指针。 - 接着,通过移动栈顶指针 (Stack Pointer) 为局部变量 (
char buffer[24]) 分配空间。 因此,栈帧的布局从高地址到低地址依次是:函数参数、返回地址、旧的帧指针、局部变量。
S4.4
Answer: The student’s proposal is flawed and does not make the system safe. While it’s true that overflowing the buffer would no longer directly overwrite the return address that is located at a lower address, it creates new vulnerabilities. If the stack grows from low to high address, the buffer will be allocated before the return address. Overflowing the buffer would now corrupt data in the caller’s stack frame, which could include the caller’s local variables, saved registers, or even function pointers stored there. An attacker could still hijack the control flow by overwriting a function pointer in the caller’s frame or manipulate the program’s logic by changing critical variables. Therefore, this proposal only changes the attack vector but does not eliminate the danger of buffer overflows.
中英文分析: 这个提议是有缺陷的 (flawed)。学生建议将栈的生长方向从“高地址 -> 低地址”改为“低地址 -> 高地址”,认为这样缓冲区溢出就不会覆盖返回地址了。
- 优点 (Pros): 确实,在这种模型下,
buffer会被分配在比return address更低的地址。因此,向前(向高地址)溢出buffer不会直接覆盖到当前函数的返回地址。 - 缺点 (Cons): 这种做法引入了新的、同样严重的安全问题。溢出的数据会破坏调用者 (caller) 的栈帧。攻击者可以覆盖调用者栈帧中的局部变量、保存的寄存器,或者是指向函数的指针。通过改变这些关键数据,攻击者同样可以控制程序的执行流程或改变其逻辑。 结论是,这个提议仅仅是改变了攻击的向量 (attack vector),而不是从根本上解决缓冲区溢出问题。
S4.5
Answer: False. The buffer overflow occurs inside the strcpy() function, which means the return address on the stack (belonging to foo()) is overwritten during the execution of strcpy(). However, the control flow is not hijacked until foo() attempts to return. When foo() executes its ret instruction, it pops the corrupted value from the stack into the instruction pointer, causing the program to jump to the malicious code. The jump happens upon foo()’s return, not strcpy()’s return.
中英文分析: 这个说法是错误的 (False)。
- 溢出发生点: 缓冲区溢出确实发生在
strcpy()函数执行期间。在这个过程中,strcpy()不断地从源字符串复制数据到目标buffer,超出了buffer的边界,并覆盖了更高地址的内存,其中就包括为foo()函数保存的返回地址 (return address)。 - 劫持发生点:
strcpy()函数本身执行完毕后,会正常返回到foo()函数中。此时,程序的控制权还在foo()手中。只有当foo()函数执行到末尾,并执行ret(return) 指令时,它才会尝试从栈上弹出之前保存的返回地址,并跳转到该地址。由于这个地址已经被strcpy()破坏,程序流此时才会被劫持 (hijacked),跳转到攻击者指定的恶意代码。 所以,跳转是在foo()返回时发生的,而不是strcpy()返回时。
S4.6
Answer: No, this code is not safe. It fixes the stack buffer overflow problem but introduces a heap buffer overflow vulnerability. The malloc() function allocates the buffer on the heap, not the stack. The strcpy() function does not check the size of the allocated buffer (size). If the length of the string str is greater than size, strcpy() will write past the allocated heap chunk. This can corrupt the heap’s internal data structures (metadata) or overwrite adjacent data objects on the heap, leading to arbitrary code execution or denial of service.
中英文分析: 这段代码不安全 (not safe)。
- 问题修复: 通过使用
malloc,代码确实避免了栈溢出 (stack buffer overflow),因为buffer现在被分配在堆 (heap) 上。 - 新问题: 代码引入了堆溢出 (heap buffer overflow) 的漏洞。
strcpy()并不检查目标缓冲区的大小。如果外部传入的str字符串的长度大于malloc分配的size,那么多余的数据就会被写入相邻的堆内存块中。 - 后果: 这种溢出可以破坏堆的内部管理结构(元数据, metadata),比如下一个空闲块的指针。攻击者可以精心构造输入,利用堆的内存分配和释放机制来实现在任意内存地址写入任意数据,最终可能导致任意代码执行 (arbitrary code execution)。一个经典的攻击方式是利用
unlink宏。
好的,我们继续解答接下来的问题。
S4.7
这个问题解释了为什么在构造缓冲区溢出攻击时,某些返回地址 (return address) 会导致攻击失败。
- 核心原因: 关键在于返回地址的字节表示 (byte representation) 中是否包含“坏字符” (bad characters),最典型的就是空字节 (null byte,
\x00)。 - 攻击原理: 攻击载荷 (payload) 通常由
[Shellcode] + [Padding] + [Return Address]构成。当程序使用strcpy()这类字符串处理函数来复制这个载荷时,strcpy()会在遇到第一个空字节时停止复制。 - 失败案例分析: 题目中失败的地址
0xbffff300和0xbffff400,在小端序 (little-endian) 架构下,内存中的表示分别为\x00\xf3\xff\xbf和\x00\xf4\xff\xbf。它们的第一个字节就是空字节。因此,strcpy在尝试复制这个新返回地址时,会立即停止,导致返回地址没有被成功覆盖,攻击自然就失败了。 - 成功案例分析: 成功的地址,如
0xbffff250(表示为\x50\xf2\xff\xbf),其字节表示中不包含空字节,因此可以被完整地复制到栈上,成功覆盖原始返回地址,使攻击得以成功。
S4.8
这个问题要求我们构造一个能触发缓冲区溢出的攻击字符串,并指出了其中有一个陷阱。
计算偏移: 首先,计算
buffer起始地址到返回地址存储位置的距离。buffer地址:0xAABB0010- 返回地址位置:
0xAABB0050 - 距离:
0x50 - 0x10 = 0x40,即 64 字节。
构造攻击字符串: 我们的输入字符串
str需要填充这 64 字节,然后用我们自己的地址覆盖掉原来的返回地址。- 偏移 0-63: 填充物,这里应该放入我们的 Shellcode。为了提高成功率,通常在 Shellcode 前面加上一段 NOP sled (空操作指令雪橇)。
- 偏移 64-67: 覆盖返回地址。理想情况下,这里应该填入
buffer的起始地址0xAABB0010,让程序返回时跳转到我们的 Shellcode。
陷阱 (The Trap):
- 问题中的陷阱在于,目标地址
0xAABB0010在小端序下的内存表示是\x10\x00\xBB\xAA。它包含一个空字节 (\x00)。 - 由于漏洞利用是通过
strcpy函数,该函数一遇到\x00就会停止复制。这意味着当strcpy复制到我们精心构造的返回地址时,它只会写入第一个字节\x10,然后就停止了。返回地址没有被完整覆盖,攻击因此失败。 - 这就是题目中所说的“陷阱”。“幸运的人”可能在别的环境(比如不同的操作系统或编译器)下测试,其
buffer地址恰好不含\x00,于是攻击侥幸成功。但在本题给定的条件下,直接攻击是行不通的。
- 问题中的陷阱在于,目标地址
S4.9
Answer: This problem describes a heap overflow that leads to an arbitrary write primitive, which can then be used to hijack control flow. The goal is to use the overflow in buffer to corrupt the struct Node p and leverage the linked list removal code (q->next = p->next;) to overwrite the function’s return address on the stack. 这个问题展示了如何利用堆溢出 (heap overflow) 来实现任意地址写入 (arbitrary write),最终劫持程序控制流。
- 漏洞分析: 漏洞代码是
q->next = p->next;。结合前一句q = p->pre;,我们可以将这个操作理解为*(p->pre) = p->next;(因为next是结构体的第一个成员,偏移为0)。这是一个典型的“写-哪里-什么” (write-what-where) 的利用原语。- WHERE (写到哪里): 由
p->pre的值决定。 - WHAT (写什么内容): 由
p->next的值决定。
- WHERE (写到哪里): 由
- 攻击思路: 我们的目标是修改栈上的返回地址 (Return Address),其位置在
0xBBFFAACC。我们想把这个地址的值改成我们 Shellcode 的地址。- 设置 WHERE: 我们需要让
p->pre指向返回地址的存储位置。所以,我们将p->pre的值设置为0xBBFFAACC。 - 设置 WHAT: 我们需要将返回地址修改为 Shellcode 的地址。Shellcode 位于我们输入的开头,也就是
buffer的地址0x804B2220。所以,我们将p->next的值设置为0x804B2220。
- 设置 WHERE: 我们需要让
- 构造 Payload (
user_input):- 首先,计算从
buffer溢出到p需要多少字节。距离为0x804B22C0 - 0x804B2220 = 160字节。 - 构造输入字符串:
- 偏移 0 ~ 159: 放置 Shellcode,其余用垃圾数据填充,总共160字节。
- 偏移 160 ~ 163: 覆盖
p->next字段。填入 Shellcode 的地址0x804B2220(小端序)。 - 偏移 164 ~ 167: 覆盖
p->pre字段。填入目标地址0xBBFFAACC(小端序)。
- 首先,计算从
- 执行效果: 当程序执行到
q->next = p->next;时,就会把0x804B2220写入到0xBBFFAACC这个地址。这样,当函数返回时,就会跳转到我们的 Shellcode,攻击成功。这种技术是堆利用中非常经典的一种方法,常被称为 unlink exploit。

S4.10
中英文分析: 这个问题是 S4.9 的一个变体,struct Node 的结构发生了改变,在开头增加了一个 int value 成员。 新的结构体定义为:
struct Node {
int value; // 4 bytes
struct Node *next; // 4 bytes
struct Node *pre; // 4 bytes
};漏洞利用代码仍然是 q->next = p->next;,它等价于 *(p->pre + offsetof(struct Node, next)) = p->next;。在新的结构中,next 字段的偏移量 (offset) 是 4 字节。因此,这个操作现在变成了 *(p->pre + 4) = p->next;。
我们的攻击目标和 S4.9 一样:将栈上的返回地址(位于 0xBBFFAACC)修改为 Shellcode 的地址(0x804B2220)。
- 设置 WHERE (写到哪里): 我们需要让
p->pre + 4的值等于0xBBFFAACC。这意味着我们必须将p->pre的值设置为0xBBFFAACC - 4 = 0xBBFFAAC8。 - 设置 WHAT (写什么内容): 我们需要让
p->next的值等于 Shellcode 的地址0x804B2220。
构造 Payload (user_input): 从 buffer (0x804B2220) 的起始位置到 p (0x804B22C0) 的起始位置的距离仍然是 160 字节。
- 偏移 0 ~ 159: Shellcode 加上填充数据,共 160 字节。
- 偏移 160 ~ 163: 覆盖
p->value。可以是任意值。 - 偏移 164 ~ 167: 覆盖
p->next。填入 Shellcode 的地址0x804B2220。 - 偏移 168 ~ 171: 覆盖
p->pre。填入我们计算出的地址0xBBFFAAC8。
当程序执行漏洞代码时,就会把 0x804B2220 写入 0xBBFFAAC8 + 4,即 0xBBFFAACC 地址处,成功修改返回地址。
S4.11
中英文分析: 这个问题询问为什么 ASLR (Address Space Layout Randomization, 地址空间布局随机化) 会让缓冲区溢出攻击变得更加困难。
ASLR 是一种操作系统级别的安全防护机制。它的核心思想是,每次程序运行时,都将进程的关键内存区域(如栈 (stack)、堆 (heap)、共享库 (libraries))加载到内存中的一个随机的基地址 (base address) 上。
这给缓冲区溢出攻击带来了两大困难:
- 无法预测 Shellcode 地址: 在传统的栈溢出攻击中,攻击者需要将返回地址覆盖为 Shellcode 在栈上的地址。由于 ASLR 的存在,栈的起始地址每次运行都不同,因此攻击者无法预知 Shellcode 的确切地址,也就无法构造一个有效的返回地址。
- 无法使用固定的库函数地址 (Return-to-libc): 另一种常见的攻击方式是 ret2libc,即不注入自己的 Shellcode,而是将返回地址覆盖为某个已知库函数(如
system())的地址。ASLR 同样会随机化共享库(如libc.so)的加载地址,导致system()这类函数的地址也随之改变,攻击者同样无法直接利用。
简而言之,ASLR 通过引入随机性,将原本确定性的攻击变成了概率性的攻击,攻击者无法再依赖硬编码的 (hardcoded) 内存地址。要绕过 ASLR,攻击者通常需要配合使用其他漏洞,例如信息泄露 (information leak) 漏洞来先获取一个随机化后的地址,然后通过相对偏移计算出其他所需地址。
S4.12
中英文分析: 这个问题询问 Shellcode 是如何在开启 ASLR 的情况下,不硬编码地址就能获得字符串 "/bin/sh" 的地址的。
这通常通过编写位置无关代码 (Position-Independent Code, PIC) 来实现。一种经典的技术是 “call-pop” 技巧:
- 在 Shellcode 中,将字符串
"/bin/sh"放置在一条call指令的紧后方。 call指令在执行时,会将其下一条指令的地址(也就是"/bin/sh"字符串的起始地址)压入栈中,然后跳转到目标地址。call的跳转目标是 Shellcode 中的另一段代码。这段代码的第一条指令就是一个pop指令。pop指令会将刚刚压入栈中的地址(即"/bin/sh"的地址)弹到一个寄存器中。
示例汇编代码结构:
jmp get_string ; 短跳转,跳过 call 指令和字符串
do_stuff:
pop esi ; 将 "/bin/sh" 的地址从栈中弹出到 esi 寄存器
; ... 接下来就可以使用 esi 寄存器中的地址来调用 execve 系统调用
get_string:
call do_stuff ; 将下一条指令的地址 ("/bin/sh") 压栈
db '/bin/sh', 0 ; 字符串数据通过这种方式,Shellcode 在运行时动态地计算出所需字符串的地址,完全不依赖于其在内存中的绝对位置,从而有效地绕过了 ASLR 带来的地址不确定性问题。
S4.13
中英文分析: 这个问题是 S4.8 的后续,询问在覆盖返回地址时,可以使用的最小地址值是多少。
在典型的缓冲区溢出攻击中,为了提高成功率,我们通常会在 Shellcode 的前面放置大量的 NOP (No-Operation) 指令(其机器码通常是 0x90)。这段区域被称为 NOP sled (NOP 雪橇)。
这么做的目的是,我们不再需要精确地将返回地址指向 Shellcode 的第一条指令。只要返回地址指向 NOP sled 中的任意一个位置,CPU 就会像滑雪橇一样顺着 NOP 指令一直执行下去,最终到达并执行我们的 Shellcode。
因此,我们可以使用的最小地址值就是我们所控制的缓冲区的起始地址,即 0xAABB0010。我们将返回地址设置为这个值,程序跳转后就会落入我们布置的 NOP sled 的最开头,从而确保攻击能够成功。
(注意:此题的讨论忽略了 S4.8 中提到的 \x00 陷阱,仅就 NOP sled 原理进行作答。)
S4.14
中英文分析: 这是一个更具挑战性的栈溢出问题,因为缓冲区 buffer 的大小 X 是一个在 范围内的未知数。我们需要构造一个通用的 (universal) 攻击字符串,无论 X 的具体值是多少,都能攻击成功。
挑战: 由于 X 不确定,返回地址相对于 buffer 起始点的偏移量 (X + 8 + 4字节的旧EBP) 也是不确定的。我们无法精确定位返回地址并只覆盖那 4 个字节。
解决方案: 我们的策略是大面积覆盖。我们构造一个足够长的攻击字符串,确保它能覆盖所有可能的返回地址位置,并将这些位置全部改写成我们想要的值。
- 选择目标地址: 我们希望程序跳转到我们的 Shellcode。最可靠的跳转目标是
buffer的起始地址0xAABBCC10,因为我们会在那里放置一个 NOP sled。 - 构造 Payload: 我们的输入字符串
str(最大300字节)应该这样构造:- 第一部分 (例如,偏移 0-99): 放置一个足够长的 NOP sled。这是一个安全的着陆区。
- 第二部分 (例如,偏移 100-149): 放置我们的 Shellcode。
- 第三部分 (例如,偏移 150-299): 用我们的目标返回地址
0xAABBCC10重复填充剩余的所有空间。[0xAABBCC10][0xAABBCC10][0xAABBCC10]...
工作原理:
strcpy会将我们这 300 字节的 payload 复制到栈上,从0xAABBCC10开始。- 无论
X是 20 还是 100,真实的返回地址总是位于被我们 payload 的第三部分(重复地址区)所覆盖的内存区域内。 - 因此,原始的返回地址一定会被
0xAABBCC10这个值所覆盖。 - 当
bof函数返回时,它会从栈上弹出0xAABBCC10并跳转过去。 - 程序执行流跳转到我们 NOP sled 的开头,然后滑向并执行 Shellcode,攻击成功。
这种方法通过牺牲 payload 的一些空间,换取了对目标内存布局不确定性的容忍,是攻击真实世界程序时常用的一种技巧。
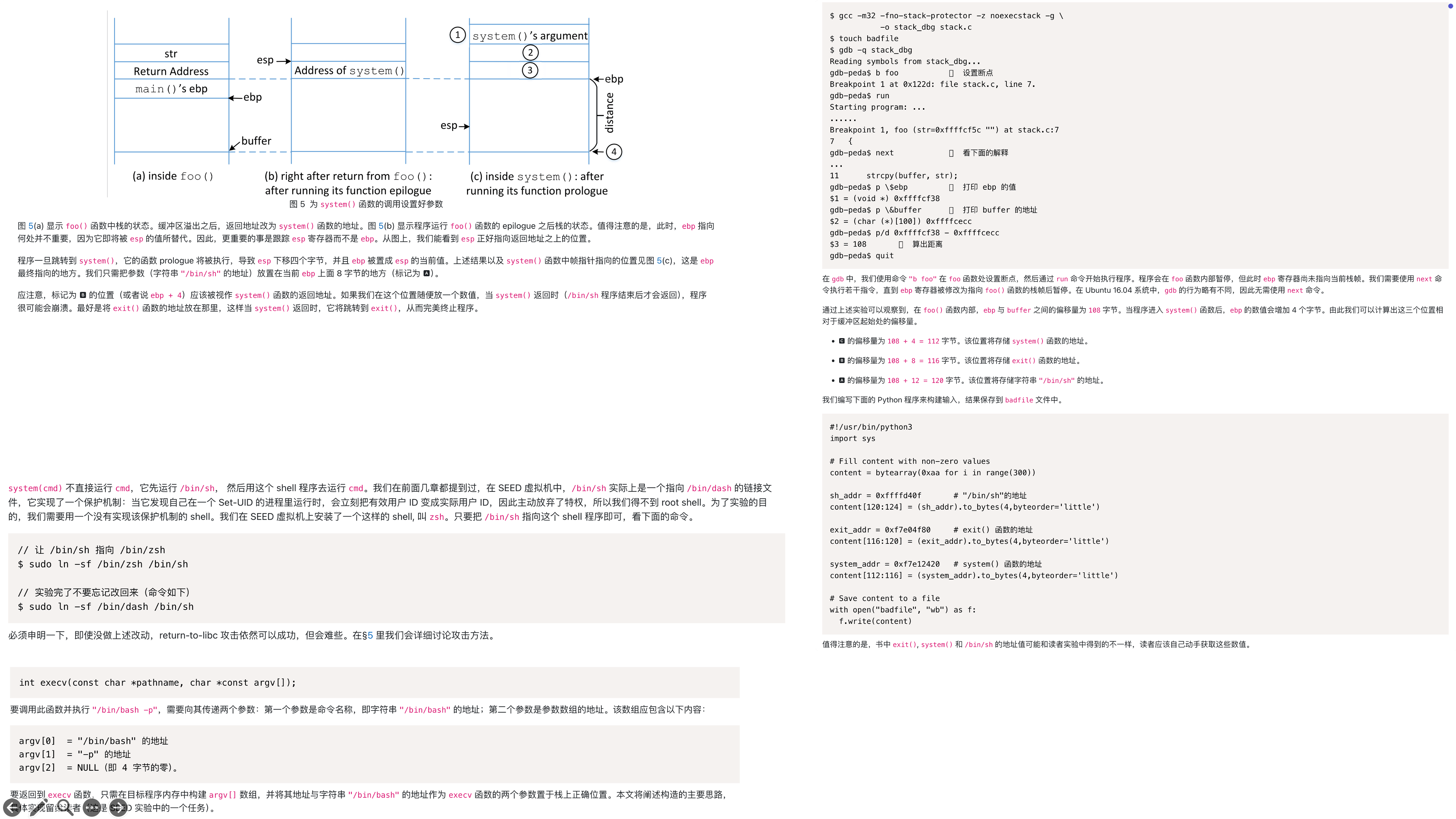
Return-to-libc (ret2libc) 基础
char buffer[sizeof(code)];
strcpy(buffer, code); 🢀 把代码拷贝到栈上
((void(*)( ))buffer)( ); 🢀 执行代码
sudo apt-get install execstack 🢀 安装 execstack 工具
$ execstack -s a.out
$ gcc -m32 -fno-stack-protector -z noexecstack -o stack stack.c
$ sudo sysctl -w kernel.randomize_va_space=0
$ sudo chown root stack
$ sudo chmod 4755 stack老四样
-fno-stack-protector: 该选项令编译器不打开 StackGuard 保护机制。如果 StackGuard 开启,利用缓冲区溢出漏洞将很困难。-z noexecstack:该选项打开不可执行栈机制,这是我们本次攻击的目标。m32选项表示我们将程序编译为 32 位二进制文件,我们使用 32 位程序来解释返回到 libc 攻击的工作原理。sysctl:该命令关闭地址空间布局随机化 (ASLR) 保护机制。如果该机制被打开,猜测返回地址的内存位置将会很困难。问题背景: 传统的缓冲区溢出攻击是在栈上注入并执行 shellcode。现代操作系统引入 NX (No-eXecute) 位 / DEP (Data Execution Prevention) 技术,将栈、堆等数据段标记为不可执行。即使能注入 shellcode,也无法执行。
绕过思路: 借刀杀人。既然不能执行栈上的代码,就跳转去执行内存中已存在的合法代码片段。
攻击目标: libc.so (Linux C 标准库) 是理想目标。它几乎被所有程序动态链接加载,且包含大量高权限操作函数,如 system()。
攻击本质: 一种 代码重用攻击 (Code Reuse Attack)。通过覆盖函数返回地址,劫持程序控制流,使其跳转到 libc 中的函数(如 system)执行攻击者指定的命令。
要成功实现 system(“/bin/sh”) 的调用,必须在内存中精确布局,解决三个关键问题:
任务 A: system() 函数的地址
获取方法: 在 ASLR 关闭的情况下,使用 GDB 调试目标程序,在程序运行后 (run 命令),使用 p system 打印其在内存中的地址。
痛点:
libc 加载基址受 ASLR 影响。
- 对于 Set-UID 程序,其动态链接库加载地址可能与非 Set-UID 程序不同,调试时需使用目标程序本身。

任务 B: “/bin/sh” 字符串的地址
植入与定位:
环境变量法: 在执行漏洞程序前,通过 export 定义一个包含 “/bin/sh” 的环境变量。该变量会存在于子进程(目标程序)的内存空间中。
缓冲区法: 将字符串直接放在溢出数据中,计算其在栈上的绝对地址(适用于缓冲区足够大的情况)。
痛点: 环境变量在栈上的地址受程序名长度、其他环境变量等因素影响,导致地址发生偏移。需要确保计算地址的环境与攻击环境一致。
任务 C: system() 函数的参数传递 (核心难点)
原理: IA-32 架构下,函数参数通过栈从右至左压入。被调用函数通过 ebp + 8 访问第一个参数,ebp + 12 访问第二个,以此类推。
挑战: ret2libc 是通过 ret 指令“骗”程序跳转,并未执行正常的 call 指令,因此没有为 system 函数准备好参数。
解决方案: 必须在溢出时,手动在栈上构造一个伪造的栈帧,使得当 system() 函数开始执行时,其 ebp 指向一个我们可控的位置,并且在 (新的ebp) + 8 的位置正好是我们准备好的 “/bin/sh” 字符串的地址。
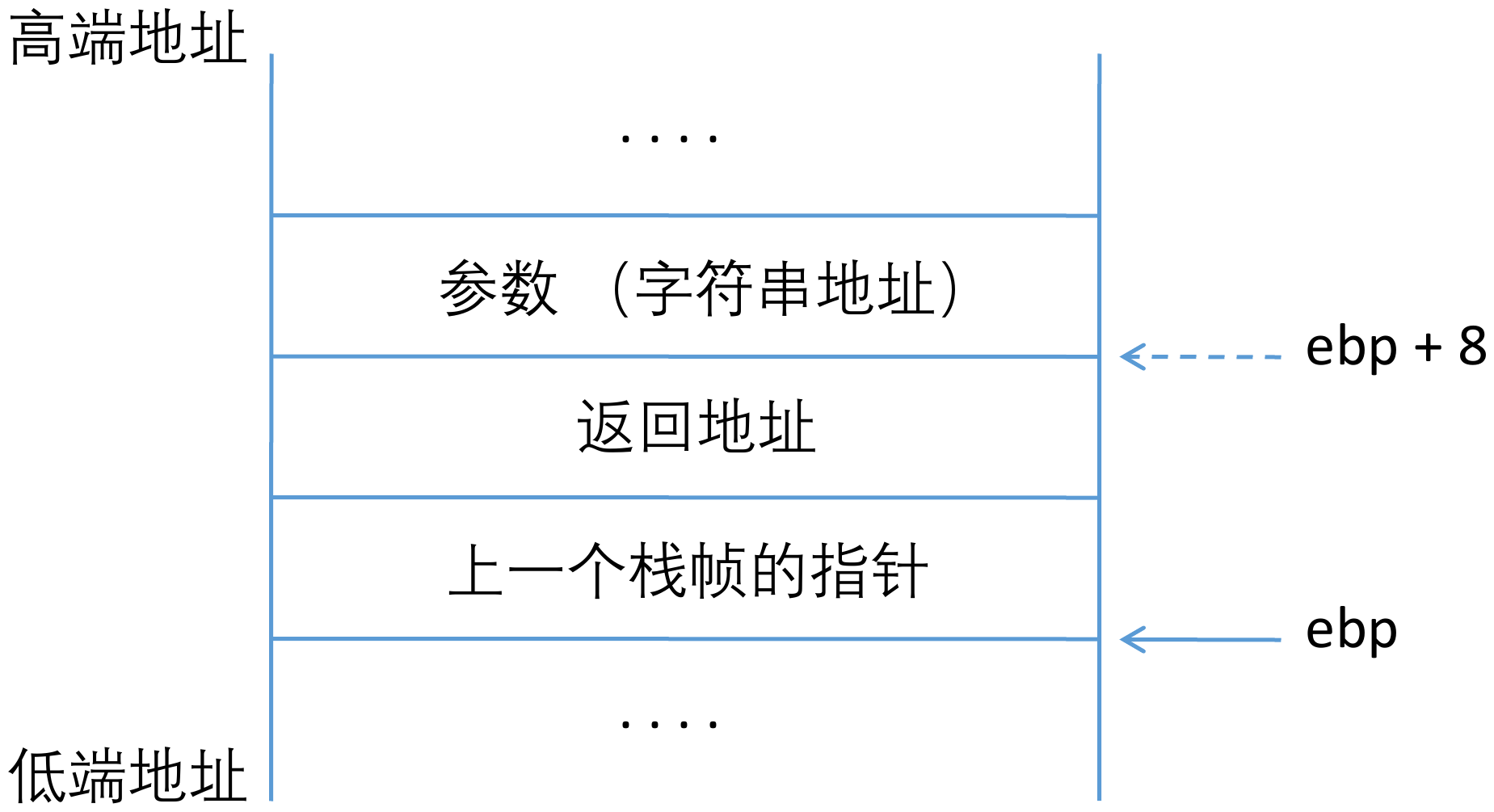
理解 prologue 和 epilogue 是构建 payload 的关键。
函数调用过程 (caller -> callee):
参数压栈。
call指令:将返回地址压栈,并跳转到函数入口。
Callee Prologue (函数序言):
push ebp: 保存调用者 (caller) 的栈帧基址。
mov ebp, esp: 设置当前函数 (callee) 的栈帧基址,ebp 指向栈底。
sub esp, N: 为局部变量分配空间。
函数返回过程 (callee -> caller):
Callee Epilogue (函数尾声):
mov esp, ebp / leave: 释放局部变量空间。
pop ebp: 恢复调用者 (caller) 的栈帧基址。
ret指令:从栈顶弹出返回地址,并跳转。
ret2libc Payload 结构:
codeCode
| ... 高地址 ... | +-------------------------+ | "/bin/sh" 字符串的地址 | <-- (system函数的ebp) + 8 +-------------------------+ | system()的返回地址(exit) | <-- (system函数的ebp) + 4 +-------------------------+ | system()地址 | <-- 被覆盖的原函数返回地址 +-------------------------+ | ... 填充 ... | +-------------------------+ | buffer 起始 | | ... 低地址 ... |偏移计算 (考点):
foo() 内: 用 GDB 找到 buffer 地址和 foo() 的 ebp 地址,计算距离 D = ebp - &buffer。
foo() 返回时: 执行 pop ebp 和 ret,esp 增加。
进入 system() 时: system() 的 prologue (push ebp; mov ebp, esp) 执行后,system() 的 ebp 值会比 foo() 的 ebp 值略高(具体取决于栈布局,通常是低4字节)。
精确布局:
覆盖返回地址的位置是 &buffer + D + 4。这里填 system() 的地址。
system() 的 “返回地址” 位于 &buffer + D + 8。为防止崩溃,通常填 exit() 的地址。
system() 的第一个参数地址位于 &buffer + D + 12。这里填 “/bin/sh” 字符串的地址。
- 最终Payload: padding [D字节] + fake_ebp [4字节] + system_addr [4字节] + exit_addr [4字节] + shell_addr [4字节]
关于system拿/bin/sh没有root权限的问题,可以用execve系方法实现,但是构建参数数组由于0的影响会比较麻烦
面向返回编程 (ROP) - 攻击的泛化
ROP解决如下问题
功能单一: 基础的 ret2libc 攻击通常只能调用一个函数(如 system)。虽然可以通过精心构造栈帧链接 exit,但实现复杂逻辑(如 A() -> B() -> C())几乎不可能。
依赖特定函数: 攻击严重依赖 system 等“神级”函数。如果目标环境的 libc 中没有这类便捷的函数,或者函数行为受限(见下一条),攻击就会失败。
Shell 防护机制: 现代 shell (如 dash, bash) 具备安全特性。当检测到自身在 Set-UID 进程中运行 (euid != uid) 时,会自动放弃特权。这导致即使成功调用 system(“/bin/sh”),也无法获得 root shell。
ROP 的诞生: 为了克服以上限制,需要一种能链式调用多个函数或执行零散指令来完成复杂任务的技术。ROP (Return-Oriented Programming) 应运而生,它将 ret2libc 的思想从“返回到函数”泛化为“返回到任意指令片段”。
我们定义
- Gadget (小工具/指令片段): ROP 的基本执行单元。它不是完整的函数,而是内存中以 ret 指令结尾的一小段指令序列。
- 来源: libc 库或程序自身的可执行代码段中。
- 特点: 执行一个或多个简单操作(如 pop eax、add esp, 8),然后通过 ret 将控制权交给栈上下一个地址。
- ROP Chain (调用链) / ROP 栈帧:
- 核心思想: 攻击者在栈上精心排列一系列 Gadget 的地址和Gadget 需要的数据。
- 执行流程:
- 第一个 ret 指令将 EIP 指向第一个 Gadget 的地址。
- 第一个 Gadget 执行,完成其任务(例如,将栈上的一个值 pop 到寄存器中)。
- 第一个 Gadget 结尾的 ret 指令,会将此时栈顶的第二个 Gadget 地址弹出到 EIP 中。
- 程序跳转执行第二个 Gadget,如此循环往复。
- 本质: 栈不再仅仅是数据区,而是被攻击者变成了一个伪造的指令流。ret 指令成了连接各个 Gadget 的“胶水”。
x64 架构的函数调用约定与 x86 (IA-32) 完全不同,导致 ROP 攻击方式产生根本性变化。
参数传递方式:
- x86: 所有参数通过栈传递。
- x64: 前 6 个整型/指针参数通过寄存器传递,顺序为:RDI, RSI, RDX, RCX, R8, R9。后续参数才使用栈。
攻击思路转变:
- 在 x86 中,我们只需在栈上排列好参数即可。
- 在 x64 中,调用函数(如 system)之前,必须先找到能够控制 RDI, RSI 等寄存器的 Gadgets。
- 关键 Gadget: pop rdi; ret 是 x64 ROP 中最重要的 Gadget。它能将我们放在栈上的值弹入 RDI 寄存器,从而控制函数的第一个参数。
x64 Payload 示例 (调用 system(“/bin/sh”)):
| ... 高地址 ... | +-------------------------+ | 函数地址 (system) | +-------------------------+ | "/bin/sh" 字符串的地址 | --> 将被 pop rdi; ret 弹入 RDI +-------------------------+ | pop rdi; ret Gadget 地址| --> ret 到这里,为 RDI 赋值 +-------------------------+ | ... 填充 + RBP ... | +-------------------------+ | buffer 起始 | | ... 低地址 ... |地址中的零字节问题:
- x64 地址是 8 字节,但通常只使用低 48 位(Canonical Address)。这意味着高位字节经常是 0x00。
- 如果漏洞利用了 strcpy 等遇 \x00 截断的函数,Payload 中一旦出现 \x00 就会导致后续数据无法复制,攻击失败。这对 Gadget 地址的选择和 Payload 的构造提出了更高的要求。
绕过 Shell 保护:
- 思路: 不调用 system,而是链式调用 setuid(0) 和 execve(“/bin/sh”, NULL, NULL)。
- 实现: 需要构建更长的 ROP 链,依次为 setuid 和 execve 的参数寄存器(RDI, RSI, RDX)赋值。
链式函数调用 (leaveret 技法):
- 目标: 实现 A(arg1) -> B(arg2) 这样的调用链。
- leave; ret Gadget: 这是一条非常有用的指令组合。leave 等价于 mov esp, ebp; pop ebp,用于恢复调用者的栈帧。
- 原理: 通过精心构造多个伪造的栈帧,并利用 leaveret Gadget 在它们之间跳转,可以实现函数链的调用和参数传递。每个伪造的栈帧都包含下一个函数的参数、leaveret Gadget地址以及下一个栈帧的地址 (新的 ebp)。
动态构造参数 (写内存 Gadget):
- 场景: 需要的参数(如 NULL)因为 \x00 无法直接放入 Payload。
- 方法: 寻找可以写内存的 Gadget,如 mov [rax], rdx; ret。先通过 pop Gadgets 将目标地址和要写入的值加载到 rax 和 rdx,然后调用写内存 Gadget,动态地在内存(如 .bss 段)中构造出需要的参数,最后再在 ROP 链中使用该参数的地址。
总结: ROP 的能力是图灵完备的。只要能找到足够丰富的 Gadgets,攻击者理论上可以执行任意复杂的逻辑,而无需注入任何自己的代码。这使得它成为绕过 NX/DEP 防护的最强大和最通用的技术。
ret2libc例题


S5.1. After using the “-z noexecstack” option to compile a C program, a buffer-overflow attack that causes the vulnerable program to return to the code on the stack is supposed to fail, but some students find out that the attack is still successful. What could be the reason?
分析 (Analysis):
原因是学生们使用的不是传统的 Shellcode-on-Stack (堆栈上的 Shellcode) 攻击,而是 Return-to-libc 攻击。
-z noexecstack选项启用了 NX bit (No-Execute bit, 不执行位),它将堆栈 (stack) 标记为不可执行 (non-executable)。- 传统的 Shellcode 攻击依赖于堆栈是可执行的,程序跳转到堆栈上的恶意代码 (shellcode)。
- Return-to-libc 攻击 则是将程序的返回地址 (Return Address) 覆盖为库函数 (library function),例如
system()的地址。因为库函数的代码位于内存中固定的、标记为可执行的.text段,而不是堆栈上,所以 NX bit 对这种攻击无效。
S5.2. …when we overflow the return address, the previous frame pointer region is already modified, so after the function epilogue, ebp contains some arbitrary value. Does this matter?
分析 (Analysis):
不重要 (It does not matter)。
- 函数 Epilogue (函数尾声) 通常包括
leave和ret指令。 leave指令相当于mov esp, ebp(恢复堆栈指针) 和pop ebp(恢复调用者 Caller 的 EBP)。ret指令则弹出 (pop) 堆栈顶部的数值,将其作为新的 EIP (Instruction Pointer, 指令指针) 并跳转。- 在 Return-to-libc 攻击中,程序流程在执行完被攻击函数的
ret指令后,立即跳转到攻击者指定的地址 (例如system()的地址)。此时,控制流已经被劫持。ebp寄存器在ret之前被恢复成一个被溢出数据覆盖的任意值,但这个值对后续的攻击执行链 (exploitation chain) 没有影响。
S5.3. Instead of jumping to the system() function, we would like to jump to the execve() function to execute “/bin/sh”. Please describe how to do this. You are allowed to have zeros in your input…
分析 (Analysis):
execve() 的函数原型是 execve(const char *pathname, char *const argv[], char *const envp[]),需要三个参数。由于允许使用零字节 (zero bytes, 因为使用了 memcpy()),我们可以构建一个完整的参数堆栈:
- 在缓冲区或其他可写/可预测的内存位置,写入以 NULL 结尾的字符串:
"/bin/sh\x00"。记录其地址 。 - 在其附近构造
argv数组: 后跟一个 4 字节的 NULL (0x00000000)。记录这个数组的起始地址 。 envp参数使用 4 字节的 NULL (0x00000000)。- 构造堆栈:
| Offset | Value | Description (描述) |
|---|---|---|
| … | Padding | 填充,直到覆盖 Ret Address |
| Ret Addr | execve() Address | 跳转目标地址 |
| Ret+4 | Fake Return Address | 假返回地址 (例如 exit() 地址) |
| Ret+8 | Arg 1: pathname 地址 | |
| Ret+12 | Arg 2: argv 数组地址 | |
| Ret+16 | 0x00000000 | Arg 3: envp (NULL) |
S5.4. …Recent versions of bash will drop the privilege if it detects that the effective user ID and the real user ID are different… please describe how you can overcome this challenge.
分析 (Analysis):
要克服权限降级 (privilege dropping) 的挑战,需要在调用 system() 之前先将 eUID (Effective User ID, 有效用户 ID) 设置为 0 (root) 并使其等于 rUID (Real User ID, 真实用户 ID)。这需要使用 Return-to-libc 链式调用 (Chained Return-to-libc)。
- 第一步:调用
setuid(0)(或seteuid(0))。- 将返回地址覆盖为
setuid()地址。 - 将
setuid()的假返回地址设置为system()地址。 - 将参数设置为 0x00000000 (即 0)。
- 将返回地址覆盖为
- 第二步:调用
system("/bin/sh")。- 当
setuid(0)返回时,控制流会跳转到其假返回地址,即system()函数的入口。 - 此时 eUID = rUID = 0,Bash 不会降级权限。
- 将
system()的假返回地址设置为任意值 (例如exit()地址)。 - 将参数设置为
"/bin/sh"字符串的地址 。
- 当
| Stack Offset | Value | Description (描述) |
|---|---|---|
| … | Padding | 填充,直到覆盖 Ret Address |
| Ret Addr | setuid() Address | 1st Jump: Call setuid |
| Ret+4 | system() Address | setuid’s Fake Ret (2nd Jump) |
| Ret+8 | 0x00000000 | setuid’s Arg: 0 |
| Ret+12 | exit() Address | system’s Fake Ret (Final Ret) |
| Ret+16 | system’s Arg: “/bin/sh” address |
S5.5. …instead of jumping to the beginning of the system() function, an attacker causes the program to jump to the first instruction right after the function prologue…
分析 (Analysis):
通常,函数 Prologue (序言) 是 push ebp 和 mov ebp, esp。跳过 Prologue 意味着 ebp 不会被更新,esp 也不会像 push ebp 那样被减小。
- 参数读取 (Argument Access): 库函数 (如
system()) 通常使用堆栈相对寻址 ([esp+N]或[ebp+N]) 来访问参数。在cdecl调用约定中,参数在返回地址 (Return Address) 之后。 - 影响: 如果跳过 Prologue,
ebp仍然指向前一个函数的基址。但只要system()函数体内部使用相对于esp(堆栈指针) 的地址来获取参数,或者使用相对于ebp的地址,而其获取参数的偏移量(offset)不受 Prologue 影响,那么攻击依然会成功。 - 构造: 堆栈布局与标准 Return-to-libc 相同。只需要将返回地址改为
system()函数的 非 prologue 入口点地址 即可。
| Stack Offset | Value | Description (描述) |
|---|---|---|
| … | Padding | 填充,直到覆盖 Ret Address |
| Ret Addr | 跳转目标:system() 的非序言地址 | |
| Ret+4 | exit() Address | 假返回地址 (Fake Return Address) |
| Ret+8 | system’s Arg: “/bin/sh” address |
S5.6. Can address space layout randomization help defeat the return-to-libc attack?
分析 (Analysis):
可以 (Yes),但不能完全消除。
ASLR (Address Space Layout Randomization) 随机化了共享库 (shared library, 如 libc.so) 在内存中的基址 (base address)。Return-to-libc 攻击依赖于知道 system() 等关键函数的绝对内存地址。如果 ASLR 开启,攻击者将无法事先得知这些地址,从而导致攻击失败。但是:
- 如果攻击者能够找到一个 Information Leak (信息泄露) 漏洞,泄露出一个库函数的地址,他们就可以推算出所有其他库函数的地址 (因为它们之间的相对偏移是固定的),从而绕过 ASLR。
- ROP 攻击 (Return-Oriented Programming) 结合信息泄露是绕过 ASLR 的常用方法。
S5.7. Does ASLR in Linux randomize the addresses of library functions, such as system()?
分析 (Analysis):
是的 (Yes)。
ASLR 随机化的是整个共享库 (shared library) 在内存中的加载基址 (base address)。由于库函数 (如 system()) 位于共享库内部,其在内存中的绝对地址会随着基址的随机化而改变。然而,库函数相对于共享库起始地址的偏移量 (offset) 保持不变。
S5.8. Assuming that we do not have the function system() that we can return to… we know the instruction sequence A, B, and C… all end in a ret instruction… Please describe what other values that you would place on the stack, so when the sub-sequence A returns, it will jump to the sub-sequence B, and when the sub-sequence B returns, it will jump to the sub-sequence C.
分析 (Analysis):
这就是 ROP (Return-Oriented Programming) 的核心机制,通过链式调用 (chaining) 结尾是 ret 指令的代码片段 (gadgets) 来控制执行流。
- 初始跳转: 缓冲区溢出将返回地址 (Ret Addr) 覆盖为子序列 A 的地址 (0xAABB1180)。
- A -> B 跳转: 当 A 执行到它的
ret指令时,它将从堆栈中弹出下一个值作为返回地址。为了跳转到 B,A 的假返回地址 (Fake Return Address) 应该被设置为 B 的地址 (0xAABB2290)。 - B -> C 跳转: 当 B 执行到它的
ret指令时,它将从堆栈中弹出下一个值。为了跳转到 C,B 的假返回地址应该被设置为 C 的地址 (0xAABB33A0)。
| Stack Offset | Value | Description (描述) |
|---|---|---|
| … | Padding | 填充,直到覆盖 Ret Address |
| Ret Addr | 0xAABB1180 (A) | Initial Jump (A) |
| Ret+4 | 0xAABB2290 (B) | A’s Fake Ret: Jump to B |
| Ret+8 | 0xAABB33A0 (C) | B’s Fake Ret: Jump to C |
| Ret+12 | Arbitrary Value | C’s Fake Ret (e.g., exit address) |
S5.9. Function foo() has a buffer overflow problem… We would like to get it to return to a sequence of function calls: bar () → bar() → bar() → xyz(3, 5) → exit().
分析 (Analysis):
这是一个函数调用链 (Function Call Chain) 的构造。在 x86 架构的 C 调用约定中,函数参数被压入堆栈,位于假返回地址 (Fake Return Address) 之后。
bar()函数没有参数,只需要其地址和下一个要跳转的地址。xyz(3, 5)需要两个参数:3 和 5。
假设 是 bar() 地址, 是 xyz() 地址, 是 exit() 地址。
|-----------------------------------|
| Padding |
|-----------------------------------|
| A_bar (bar() addr) | <-- Ret Address (EIP jumps here)
|-----------------------------------|
| A_bar (Fake Ret for bar 1) | <-- bar() ret pops this, jumps to bar 2
|-----------------------------------|
| A_bar (Fake Ret for bar 2) | <-- bar() ret pops this, jumps to bar 3
|-----------------------------------|
| A_xyz (Fake Ret for bar 3) | <-- bar() ret pops this, jumps to xyz(3, 5)
|-----------------------------------|
| A_exit (Fake Ret for xyz) | <-- xyz() ret pops this, jumps to exit()
|-----------------------------------|
| 3 (0x00000003) | <-- xyz()'s 1st argument
|-----------------------------------|
| 5 (0x00000005) | <-- xyz()'s 2nd argument
|-----------------------------------|
| ... |
|-----------------------------------|
| <-- ebp of foo() |S5.10. Function foo() has a buffer overflow problem… return to a library function xyz(0). You cannot skip xyz()‘s function prologue; nor can you put any zero in your input… There is another library function called setzero(addr)…
分析 (Analysis):
无零字节限制 (No zero byte constraint) 是关键。我们需要一个 0 作为 xyz(0) 的参数,但不能直接将 0x00000000 放入输入流中。因此,我们必须利用 setzero(addr) 在运行时 (runtime) 在堆栈上创建一个 0。
- Payload 1: 调用
setzero。参数是下一个函数xyz(0)所需参数在堆栈上的位置 (地址 )。 - Payload 2: 调用
xyz。其参数槽 () 已经被setzero函数清零。
- 是
setzero()地址。 - 是
xyz()地址。 - 必须是堆栈上位于
xyz的假返回地址之后的一个地址,它必须是一个非零地址,但其内容在setzero运行后会变为零。
|-----------------------------------|
| Padding |
|-----------------------------------|
| A_setzero (setzero addr) | <-- Ret Address (EIP jumps here)
|-----------------------------------|
| A_xyz (Fake Ret for setzero) | <-- setzero() ret pops this, jumps to xyz(0)
|-----------------------------------|
| A_arg_slot (& Arg_slot) | <-- setzero()'s Arg: Address of the memory slot to zero
|-----------------------------------|
| 0xDEADBEEF (Fake Ret for xyz) | <-- xyz() ret pops this (Placeholder, must be non-zero in input)
|-----------------------------------|
| Initial_Non_Zero_Value | <-- A_arg_slot points here. setzero() writes 0x00000000 here.
| | <-- xyz() reads this as its Arg: 0x00000000
|-----------------------------------|
| ... |
|-----------------------------------|
| <-- ebp of foo() |S5.11. …return to a library function sequence xyz (0x11111111) → xyz (0) → xyz(0x22222222). You cannot skip xyz()‘s function prologue; nor can you put any zero in your input…
分析 (Analysis):
这需要一个更复杂的 ROP 链,结合 S5.10 的零字节创建技术。我们需要在第二个 xyz(0) 被调用之前,将它的参数槽清零。
- Call 1:
xyz(0x11111111)。参数 0x11111111。返回地址是setzero。 - Call 2:
setzero(A_{arg\_slot2})。清零第二个xyz的参数槽。返回地址是第二个xyz。 - Call 3:
xyz(0)。参数槽已清零。返回地址是第三个xyz。 - Call 4:
xyz(0x22222222)。参数 0x22222222。返回地址是最终的退出地址。
- 是
xyz()地址。 - 是
setzero()地址。 - 是第二个
xyz的参数槽地址。
|-----------------------------------|
| Padding |
|-----------------------------------|
| A_xyz (xyz addr) | <-- Ret Address (EIP jumps to 1st xyz)
|-----------------------------------|
| A_setzero (Fake Ret for 1st xyz) | <-- 1st xyz() ret pops this, jumps to setzero
|-----------------------------------|
| 0x11111111 | <-- 1st xyz()'s Arg
|-----------------------------------|
| A_xyz (Fake Ret for setzero) | <-- setzero() ret pops this, jumps to 2nd xyz
|-----------------------------------|
| A_arg_slot2 (& Arg_slot2) | <-- setzero()'s Arg: Address to zero
|-----------------------------------|
| A_xyz (Fake Ret for 2nd xyz) | <-- 2nd xyz() ret pops this, jumps to 3rd xyz
|-----------------------------------|
| Initial_Non_Zero_Value | <-- A_arg_slot2 points here. setzero() writes 0x00000000 here.
| | <-- 2nd xyz() reads this as its Arg: 0x00000000
|-----------------------------------|
| 0xDEADBEEF (Fake Ret for 3rd xyz)| <-- 3rd xyz() ret pops this (Final Ret)
|-----------------------------------|
| 0x22222222 | <-- 3rd xyz()'s Arg
|-----------------------------------|
| ... |
|-----------------------------------|
| <-- ebp of foo() |